Data is critical for the effective operation of our AI models. Having an abundance of data is one of the ideal conditions for our models.
Synth is a platform that produces data closely resembling real-world data by mimicking the characteristics of actual data. This allows for a significant reduction in data collection and labeling costs. With Synth, you can:
- Save time and costs by eliminating the need for real data collection.
- Automate the labeling process, reducing reliance on human labor.
- Easily increase the volume and diversity of data.
- Fill gaps caused by missing or faulty data samples with synthetic data.
For more information, please contact us.
Synth and Synthetic Data:
Synthetic data is artificially generated data created to mimic real-world data, rather than being collected from actual events. It is designed to replicate the characteristics of real data and is ideal for training, testing, and privacy protection in AI models.
Synthetic data is revolutionizing the training of AI models. It eliminates the challenges of collecting real data, which can be difficult to find, costly, and time-consuming. This enables us to develop AI models that are faster, cheaper, and more effective.

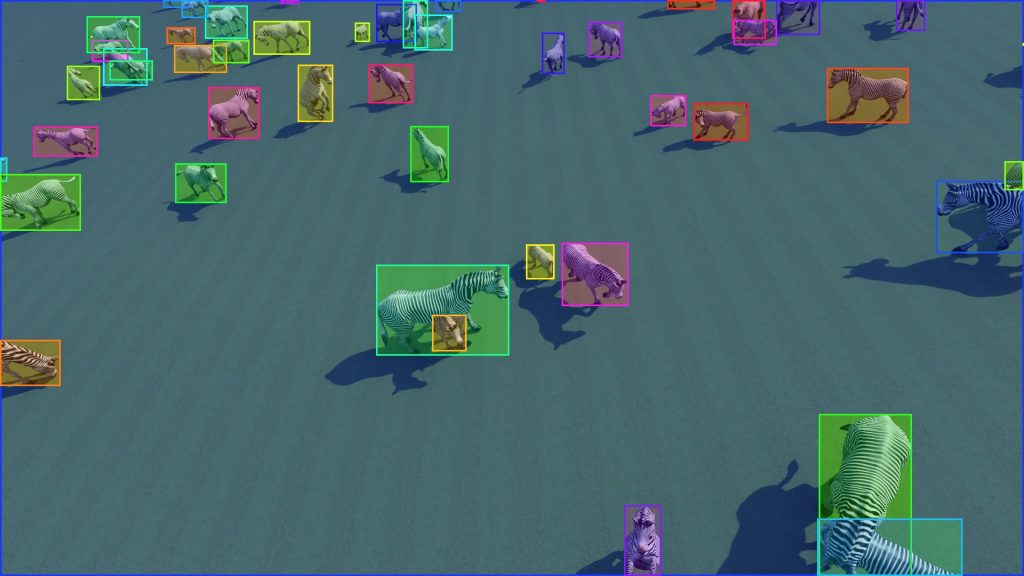
Research and Evidence
Deep learning models developed for zebras using different datasets have been examined. The results from this study are as follows:
- COCO: 47% mAP
- Real Data: 95% mAP
- Synthetic Data: 90% mAP
- Real Data and Synthetic Data Combined: 98% mAP
As seen from the research, it is possible to produce desired models using synthetic data alone, without relying solely on real data.
The research also supports that deep learning models perform better when trained on a combination of real and synthetic data.
Why Do We Need Synthetic Data?
Collecting and labeling visual data is crucial in many areas, such as 2D and 3D object detection and segmentation. However, these processes can be time-consuming, labor-intensive, and costly.
Synth offers an ideal solution to overcome these challenges.
Let’s consider an example: You’re developing an AI model that detects luggage falling onto train tracks, which could be a great safety measure for your company. However, since such scenarios are rare in real life, finding data to train your model can be quite difficult. This is where Synth comes in. In our luggage-on-train-tracks example, while finding real data might be tough, we can complete everything in a simulation environment in just two simple steps:
- Creating the Environment: We can create a simulation environment that replicates the train tracks, platform, and surrounding area using our simulations.
- Generating Data: By simulating the luggage falling onto the tracks and generating the necessary labels, we can quickly obtain the data you need.
As you can see, with synthetic data, we can successfully complete the challenging and expensive process of real data collection.
Labeling Costs
Labeling real data, meaning assigning descriptions to each data point, requires human labor, making it a costly process.
Fortunately, we can provide you with data from a simulation environment without incurring these costs.

Environmental Diversity
Consider training AI models for an autonomous vehicle. The vehicle needs to learn how to behave under various conditions, such as daytime, nighttime, and rainy weather. With Synth and synthetic data, you can prepare your AI model for all kinds of weather conditions and environments.
Advantages of Synth:

Faster and Lower-Cost Data Sets
Synth accelerates the data set creation process and reduces costs by eliminating the need for real data collection and labeling.
Data Generation for Any Model
With Synth, you can access data for:
- 2D-3D Object Detection
- Instance-Semantic Segmentation
- Depth Sensing models


More Reliable Data Privacy
There is always a risk of personal data breaches during real-world data collection. For instance, collecting facial data from people to train a face recognition model can lead to privacy violations. Since Synth generates data in a simulation environment entirely independent of the real world, it contains no personal or sensitive information, eliminating privacy concerns.
Time and Cost Savings
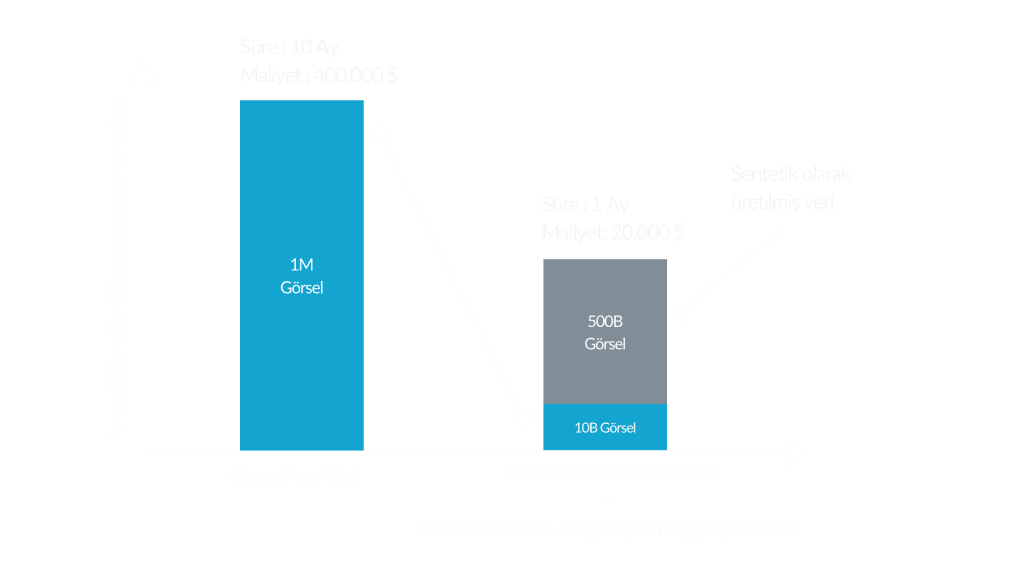
Real-world data can be difficult to collect and limited in availability, leading to time and cost disadvantages. Synthetic data, on the other hand, can be easily generated in such cases, simplifying model training and providing significant savings. For example, while it might take 10 months and $400,000 to gather 500,000 real data points, the same amount of synthetic data can be produced in 1 month for $20,000—resulting in a 100-fold cost advantage.
Synthetic data can be generated for both your specific scenarios and generalizable situations.